Analyse de données de joueurs de football à l'aide du web scraping avec C# et HtmlAgilityPack
Dans ce projet j’utilise l’environnement Jupyter Notebook avec le langage C# et la bibliothèque HtmlAgilityPack pour effectuer extraire des données du web (webscraping) du site Sofifa. Sofifa est une base de données en ligne de joueurs de football.
Analyse de données de joueurs de football à l’aide du web scraping avec C# et HtmlAgilityPack
Dans ce projet j’utilise l’environnement Jupyter Notebook avec le langage C# et la bibliothèque HtmlAgilityPack pour effectuer extraire des données du web (webscraping) du site Sofifa. Sofifa est une base de données en ligne de joueurs de football.
Extraction des données
Nous commençons par l’importation des packages nécessaires et le chargement du site Sofifa à l’aide de HtmlAgilityPack. Ensuite, nous sélectionnons les nœuds HTML contenant les informations des joueurs à l’aide de requêtes XPath. Les données importantes telles que le nom, l’âge, la note globale, l’équipe et le salaire sont extraites en utilisant des méthodes spécifiques.
Importation des packages
Nous commençons par importer HtmlAgilityPack pour le traitement HTML.
#r "nuget: HtmlAgilityPack, 1.11.60"
- HtmlAgilityPack, 1.11.60
using HtmlAgilityPack;
Chargement du site et extraction des données
Nous chargeons le site Sofifa et sélectionnons les nœuds HTML contenant les informations des joueurs à l’aide de XPath.
string sofifa = "https://sofifa.com/players";
HtmlWeb web = new HtmlWeb();
var htmlDoc = web.Load(sofifa);
string sofifa = "https://sofifa.com/players";- Cette ligne crée une variable
sofifaet lui assigne la valeur"https://sofifa.com/players". Cette URL représente la page web de Sofifa où se trouvent les informations sur les joueurs de football.
- Cette ligne crée une variable
HtmlWeb web = new HtmlWeb();- Cette ligne crée une nouvelle instance de la classe
HtmlWeb. Cette classe est fournie par la bibliothèque HtmlAgilityPack et est utilisée pour télécharger le contenu HTML d’une URL spécifiée.
- Cette ligne crée une nouvelle instance de la classe
var htmlDoc = web.Load(sofifa);- Cette ligne utilise l’instance de
HtmlWebcréée précédemment pour charger le contenu HTML de l’URL spécifiée dans la variablesofifa. Le contenu HTML est téléchargé depuis le site web et stocké dans la variablehtmlDoc. Cette variable contiendra ensuite le document HTML de la page Sofifa, ce qui permettra d’extraire les informations des joueurs à partir de celui-ci.
- Cette ligne utilise l’instance de
Nous utilisons XPath pour sélectionner les noms des joueurs dans la page HTML et les affichons.
htmlDoc.DocumentNode
.SelectNodes("//a[starts-with(@href, '/player/')]")
.Select((node, index) => (node, index))
.Take(15)
.ToList()
.ForEach(res => Console.WriteLine($"{res.index} - {res.node.InnerText}"))
0 - Random
1 - M. Wieffer
2 - Lucas Paquetá
3 - W. Odobert
4 - M. Salah
5 - C. Palmer
6 - M. O'Riley
7 - A. Isak
8 - G. Rodríguez
9 - W. Zaïre-Emery
10 - V. Gyökeres
11 - A. Güler
12 - K. Mainoo
13 - K. Havertz
14 - J. Zirkzee
Il est relativement simple avec XPATH de parcourir toute la page web et sélectionner le contenu texte d’une balise web. C’est ce que nous venons de faire pour extraire les noms des joueurs. Toutefois nous aimerons récupérer d’autres informations concernant chaque joueur.
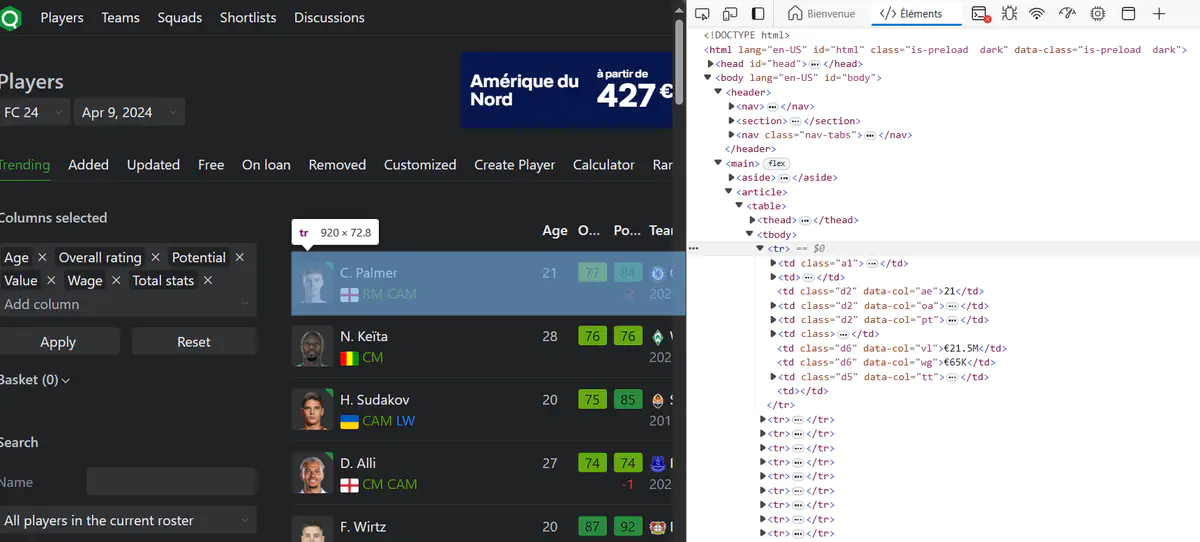
Pour cela, regardons comment la page HTML est structurée :
Je veux extraire pour chaque joueur : nom, l’âge, la note globale, l’équipe et le salaire. La strucure HTML est ainsi constituée :
- Toutes les données des joueurs sont groupées dans une balise table
- Le contenu du tableau se trouve dans la sous-balise tbody
- Les lignes pour chaque joueur apparaissent dans les balises tr
- Le contenu de chaque colonne est dans la balise td
Les données telles que l’âge et le salaire sont faciles à récupérer car nous voyons qu’elles ont explicitement des propriétés data-col définies au niveau des td.
La manière la plus sûre de récupérer les données est de procéder à l’extraction ligne par ligne, c’est à dire de prendre pour point d’entrée chaque balise tr.
Pour ce faire, nous allons dans un premier sélectionner le noeud tbody.
var tbody = htmlDoc.DocumentNode.SelectSingleNode("//tbody");
A l’aide du XPATH nous sélectionnons entièrement le noeud tbody.
Comptons le nombre de balises tr se trouvant dans ce noeud
tbody.SelectNodes("//tr").Count()
61
Il y a 61 lignes dans la page que nous explorons. Affichons un aperçu du contenu HTML des deux premières lignes.
tbody.SelectNodes("//tr")
.Select(x => x.InnerHtml)
.Take(2)
.ToList()
.ForEach(x => Console.WriteLine($"-- {x}"))
--
<th class="a1"></th>
<th class="s20">Name</th><th class="d2"><a rel="nofollow" href="/players?col=ae&sort=asc" data-tippy-top="" data-tippy-content="Age"><span class="sorter"></span>Age</a></th><th class="d2"><a rel="nofollow" href="/players?col=oa&sort=desc" data-tippy-top="" data-tippy-content="Overall rating"><span class="sorter"></span>Overall rating</a></th><th class="d2"><a rel="nofollow" href="/players?col=pt&sort=desc" data-tippy-top="" data-tippy-content="Potential"><span class="sorter"></span>Potential</a></th><th class="s20"><a rel="nofollow" href="/players?col=tm&sort=asc" data-tippy-top="" data-tippy-content="Team & Contract"><span class="sorter"></span>Team & Contract</a></th>
<th class="d6"><a rel="nofollow" href="/players?col=vl&sort=asc" data-tippy-top="" data-tippy-content="Value"><span class="sorter"></span>Value</a></th><th class="d6"><a rel="nofollow" href="/players?col=wg&sort=asc" data-tippy-top="" data-tippy-content="Wage"><span class="sorter"></span>Wage</a></th><th class="d5"><a rel="nofollow" href="/players?col=tt&sort=desc" data-tippy-top="" data-tippy-content="Total stats"><span class="sorter"></span>Total stats</a></th><th></th>
--
<td class="a1"><figure class="avatar">
<img alt="" data-src="https://cdn.sofifa.net/players/248/793/24_60.png" data-srcset="https://cdn.sofifa.net/players/248/793/24_120.png 2x, https://cdn.sofifa.net/players/248/793/24_180.png 3x" alt="" src="https://cdn.sofifa.net/player_0.svg" data-root="https://cdn.sofifa.net/" data-type="player" id="248793" class="player-check"></figure></td>
<td>
<a href="/player/248793/mats-wieffer/240038/" data-tippy-top="" data-tippy-content="Mats Wieffer">M. Wieffer</a><div><img title="Netherlands" alt="" src="https://cdn.sofifa.net/pixel.gif" data-src="https://cdn.sofifa.net/flags/nl.png" data-srcset="https://cdn.sofifa.net/flags/[email protected] 2x, https://cdn.sofifa.net/flags/[email protected] 3x" class="flag" width="21" height="16"> <a rel="nofollow" href="/players?pn=10"><span class="pos pos10">CDM</span></a> <a rel="nofollow" href="/players?pn=14"><span class="pos pos14">CM</span></a></div>
</td><td class="d2" data-col="ae">23</td><td class="d2" data-col="oa"><em title="78">78</em></td><td class="d2" data-col="pt"><em title="84">84</em></td><td class="">
<figure class="avatar small transparent">
<img alt="" class="team" data-src="https://cdn.sofifa.net/meta/team/73/30.png" data-srcset="https://cdn.sofifa.net/meta/team/73/60.png 2x, https://cdn.sofifa.net/meta/team/73/90.png 3x" src="https://cdn.sofifa.net/empty.svg" data-root="https://cdn.sofifa.net/" data-type="team">
</figure>
<a href="/team/246/feyenoord/">Feyenoord</a><div class="sub">
2022 ~ 2027</div>
</td><td class="d6" data-col="vl">€20.5M</td><td class="d6" data-col="wg">€15K</td><td class="d5" data-col="tt"><em>2050</em></td><td></td>
La première ligne ne contient pas les données des joueurs mais uniquement l’entête des données.
Nous prenons en compte cette information lorsque nous allons extraire le contenu des données. Nous sauterons la première ligne.
Définir un enregistrement (record) pour représenter une ligne
Nous définissons une classe Player pour stocker les informations de chaque joueur. Ensuite, nous créons une méthode ExtractPlayer pour extraire les données pertinentes telles que le nom, l’âge, la note globale, l’équipe et le salaire.
record Player(string Name,
int Age,
int? OverallRating,
string TeamContract,
double? Wage);
Player ExtractPlayer(HtmlNode node)
{
string name = node.SelectSingleNode(".//a[starts-with(@href, '/player/')]").InnerText;
string extractedAge = node.SelectSingleNode(".//td[@data-col='ae']").InnerText;
int.TryParse(extractedAge, out int age);
string extractedOverall = node.SelectSingleNode(".//td[@data-col='oa']").InnerText;
int.TryParse(extractedOverall, out int overall);
string contract = node.SelectSingleNode(".//a[starts-with(@href, '/team/')]").InnerText;
string extractedWage = node.SelectSingleNode(".//td[@data-col='wg']").InnerText;
extractedWage = new string(extractedWage.Where(c=> (Char.IsDigit(c) || c=='.'|| c==',')).ToArray());
double.TryParse(extractedWage, out double wage);
var player = new Player(name, age, overall, contract, wage);
return player;
}
record Player(string Name, int Age, int OverallRating, string TeamContract, double? Wage);- Cette ligne définit un enregistrement (record) nommé
Player, qui représente un joueur de football. Il a cinq propriétés :Name,Age,OverallRating,TeamContractetWage. Ces propriétés correspondent aux informations que nous extrayons pour chaque joueur.
- Cette ligne définit un enregistrement (record) nommé
Player ExtractPlayer(HtmlNode node)- Cette ligne définit une méthode appelée
ExtractPlayer, qui prend en paramètre un nœud HTML (HtmlNode). Cette méthode extrait les informations d’un joueur à partir d’un nœud HTML et les retourne sous forme d’un objetPlayer.
- Cette ligne définit une méthode appelée
string name = node.SelectSingleNode(".//a[starts-with(@href, '/player/')]").InnerText;- Cette ligne extrait le nom du joueur en recherchant une balise
<a>qui commence par l’attributhrefcontenant'/player/'à l’intérieur du nœud HTML donné, puis récupère son texte interne à l’aide de la propriétéInnerText.
- Cette ligne extrait le nom du joueur en recherchant une balise
string extractedAge = node.SelectSingleNode(".//td[@data-col='ae']").InnerText;- Cette ligne extrait l’âge du joueur en recherchant une balise
<td>avec l’attributdata-colégal à'ae'à l’intérieur du nœud HTML donné, puis récupère son texte interne à l’aide de la propriétéInnerText.
- Cette ligne extrait l’âge du joueur en recherchant une balise
int.TryParse(extractedAge, out int age);- Cette ligne tente de convertir la chaîne
extractedAgeen un entier (int). Si la conversion réussit, elle stocke la valeur dans la variableage.
- Cette ligne tente de convertir la chaîne
string extractedOverall = node.SelectSingleNode(".//td[@data-col='oa']").InnerText;- Cette ligne extrait la note globale du joueur de la même manière que l’âge.
int.TryParse(extractedOverall, out int overall);- Cette ligne tente de convertir la chaîne
extractedOverallen un entier (int). Si la conversion réussit, elle stocke la valeur dans la variableoverall.
- Cette ligne tente de convertir la chaîne
string contract = node.SelectSingleNode(".//a[starts-with(@href, '/team/')]").InnerText;- Cette ligne extrait le contrat de l’équipe du joueur en recherchant une balise
<a>qui commence par l’attributhrefcontenant'/team/'à l’intérieur du nœud HTML donné, puis récupère son texte interne à l’aide de la propriétéInnerText.
- Cette ligne extrait le contrat de l’équipe du joueur en recherchant une balise
string extractedWage = node.SelectSingleNode(".//td[@data-col='wg']").InnerText;- Cette ligne extrait le salaire du joueur de la même manière que l’âge et la note globale.
extractedWage = new string(extractedWage.Where(c=> (Char.IsDigit(c) || c=='.'|| c==',')).ToArray());- Cette ligne filtre la chaîne
extractedWagepour ne conserver que les caractères numériques, le point (.) et la virgule (,). Cela est nécessaire car le salaire peut contenir des symboles de devise ou d’autres caractères non numériques.
- Cette ligne filtre la chaîne
double.TryParse(extractedWage, out double wage);- Cette ligne tente de convertir la chaîne
extractedWageen un nombre à virgule flottante (double). Si la conversion réussit, elle stocke la valeur dans la variablewage.
- Cette ligne tente de convertir la chaîne
var player = new Player(name, age, overall, contract, wage);- Cette ligne crée une nouvelle instance de la classe
Playeravec les informations extraites du joueur.
- Cette ligne crée une nouvelle instance de la classe
return player;- Cette ligne retourne l’objet
Playercréé à partir des informations extraites.
- Cette ligne retourne l’objet
En combinant toutes ces lignes, la méthode ExtractPlayer prend un nœud HTML représentant un joueur de football, extrait ses informations et retourne un objet Player contenant ces informations.
var players = tbody
.SelectNodes("//tr")
.Skip(1)
.Select(x => ExtractPlayer(x));
Afficher les informations des joueurs
void Display(Player p) =>
Console.WriteLine($@"
Name: {p.Name}
Age: {p.Age}
Overall Rating: {p.OverallRating}
Team/Contract: {p.TeamContract}
Wage: {p.Wage}");
players
.Take(5)
.ToList()
.ForEach(p => Display(p))
Name: M. Wieffer
Age: 23
Overall Rating: 78
Team/Contract: Feyenoord
Wage: 15
Name: Lucas Paquetá
Age: 25
Overall Rating: 82
Team/Contract: West Ham United
Wage: 85
Name: W. Odobert
Age: 18
Overall Rating: 0
Team/Contract: Burnley
Wage: 10
Name: M. Salah
Age: 31
Overall Rating: 89
Team/Contract: Liverpool
Wage: 260
Name: C. Palmer
Age: 21
Overall Rating: 0
Team/Contract: Chelsea
Wage: 76
Conclusion
Ce projet démontre comment utiliser le web scraping avec C# et HtmlAgilityPack pour extraire et analyser des données à partir de sites Web. Dans cet exemple, nous avons extrait les informations des joueurs de football à partir de Sofifa, en mettant en évidence le processus de collecte, de traitement et d’affichage des données. Cette approche peut être étendue pour analyser d’autres types de données sur le web, offrant ainsi un large éventail d’applications dans le domaine de l’analyse de données et de la science des données.
Réutiliser le notebook Jupyter
J’ai rendu disponible le notebook Jupyter qui a servi dans cet article. Vous pouvez le trouver ici.